
Maschinelles Lernen: Supervised Learning
Maschinelles Lernen (ML) ist ein Teilgebiet der künstlichen Intelligenz, die mit ihrem enormen Potential einen großen Einfluss auf unser aktuelles und zukünftiges Leben haben wird. Verschiedene Methoden des maschinellen Lernens wurden spezialisiert für bestimmte Situationen und Datensätze entworfen, haben aber alle eine wichtige Gemeinsamkeit:
Sie können aus Erfahrungen lernen und sich stetig verbessern, ohne dass sie im Einzelnen dazu programmiert werden müssen1. Sie erkennen prinzipiell Zusammenhänge in (großen) Datensätzen und treffen Vorhersagen, wie es ein Mensch niemals könnte.
Diese Funktion kann auf vielen Gebieten eingesetzt werden: Von der medizinischen Anwendung zur Tumorerkennung, dem Rechts- und Steuerwesen, Marketing oder Verkehr bis zum industriellen Einsatz, um Stromkosten zu senken oder Maschinen effizienter zu warten2.
Vorgehensweise
Eine dieser Methoden wird als Supervised Machine Learning oder auch als überwachtes maschinelles Lernen bezeichnet. Um diese sinnvoll anwenden zu können, müssen Daten mit ihrem dazugehörigen Ergebnis für ein klar definiertes Ziel bzw. eine Vorhersage vorhanden sein. Hierbei sind die klare Struktur und das Wissen um die Daten und ihr Ergebnis in Bezug auf die definierte Vorhersage besonders wichtig. Die Trainingsdaten müssen für diese Methode also speziell markiert werden bzw. Labels aufweisen, damit ein Modell entwickelt werden kann. Das Modell enthält letztendlich den Zusammenhang zwischen Trainingsdaten und ihren dazugehörigen Ergebnissen in abstrahierter Form. Während des Trainings überprüft der Algorithmus immer wieder die selbst vorhergesagten Ergebnisse mit den vorhandenen Ergebnissen der Trainingsdaten und passt sein Modell entsprechend an. Das Training wird so oft wiederholt, bis das Modell die Ergebnisse mit einer ausreichenden Genauigkeit vorhersagen kann3. Das fertige Modell kann danach für eine Vorhersagen mit neuen Daten herangezogen werden.
Anwendungsbeispiel
Ein einfaches Beispiel wird dies näher erläutern: Supervised Machine Learning kann z.B. angewendet werden, um Hauspreise vorherzusagen. Eine Reihe von Hausattributen (auch Features genannt) wie Wohnfläche, Grundstückslage, Zimmeranzahl oder Schulen in der näheren Umgebung müssen bereits für eine Anzahl von Häusern verfügbar sein. Diese Daten sollten entweder direkt oder indirekt die zugehörigen Hauspreise beeinflussen. Zusätzlich müssen für die vorhandenen Daten, die auch Trainingsdaten genannt werden, die Hauspreise bekannt sein, damit dieser Zusammenhang für die Erstellung (Training) eines Modells verwendet werden kann. Nach dem Training ist das resultierende Modell mit einer gewissen Genauigkeit dazu in der Lage, die Hauspreise von neuen Häusern vorherzusagen, solange die Informationen für die entsprechenden Haus-Features vorliegen. Mit weiteren Trainingsdaten, einem besser angepassten Lernalgorithmus oder einem Datenreinigungsschritt, der falsche oder fehlende Daten entfernt, kann die Vorhersage automatisiert weiter verbessert werden. Für erfahrene Data Scientists ist der letzte Punkt einer der wichtigsten Schritte. Um ein gutes Modell zu generieren, müssen die Daten in möglichst guter Qualität vorliegen.
Algorithmen im Supervised Learning Verfahren
Auch bei der richtigen Auswahl des Machine Learning Algorithmus ist die Fachkenntnis und Erfahrung eines Machine Learning Engineers gefragt. Denn nicht jeder Algorithmus ist für alle Fragestellungen gleich gut geeignet. Er muss für die spezifische Fragestellung ausgewählt und mit entsprechenden Trainingsparametern angewendet werden, um optimale Ergebnisse zu gewährleisten. Die am häufigsten verwendeten „Supervised Machine Learning“ Algorithmen sind z.B. lineare und logistische Regression, Decision Trees, k-Nearest Neighbor Algorithmen (k-NN), Support Vector Machines (SVM) und Neurale Netze4.
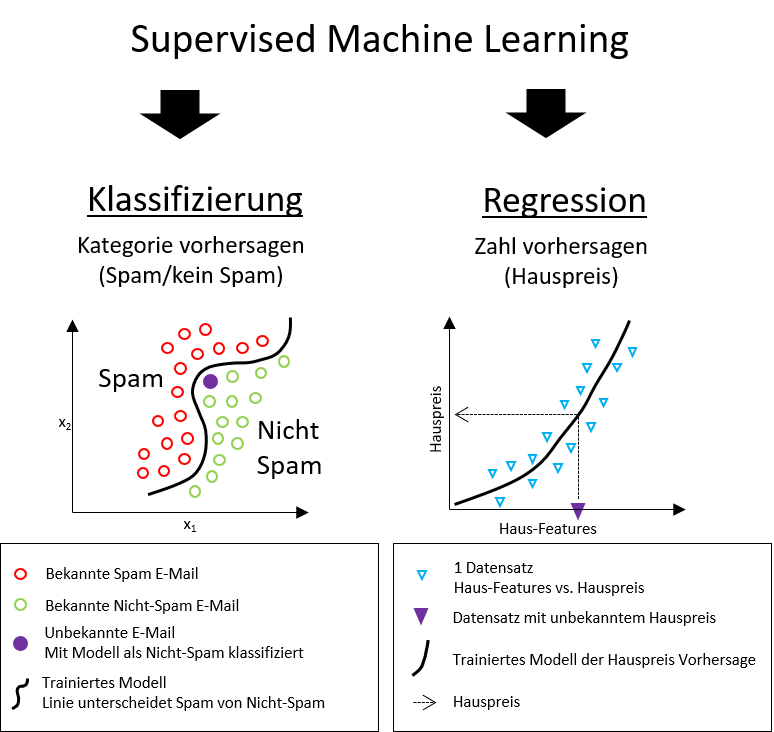
Kategorien: Klassifikation und Regression
Supervised Machine Learning wird weiter in zwei Unterkategorien eingeteilt: Klassifikations- und Regressions-Fragestellungen (Abbildung 1). Das bereits oben erwähnte Beispiel einer Hauspreis-Vorhersage veranschaulicht ein Regressionsproblem. Hier sollen Hauspreise in € als Werte eines kontinuierlichen Zahlenraums vorhergesagt werden (Abbildung 1 rechts). Die Haus-Features der Trainingsdatenpunkte werden als blaue Dreiecke auf der x-Achse repräsentiert und ihren jeweiligen Hauspreisen gegenübergestellt (y-Achse). Das trainierte Regressions-Modell wird als Linie in der 2D Grafik eingezeichnet. Einem neuen Datensatz (lila Dreieck) kann ein Hauspreis mit Hilfe der Regressions-Model-Linie zugeordnet werden (Hilfslinien-Schnittpunkt mit y-Achse). Für ein Klassifikationsproblem werden Daten bestimmten vordefinierten Kategorien zugeordnet. Hier kann als Beispiel die Zuordnung von E-Mails zu den Kategorien Spam oder Nicht-Spam herangezogen werden5 (Abbildung 1 links). Die Kategorien müssen initial definiert werden, damit ein Modell trainiert werden kann. In der Abbildung werden einzelne E-Mails in einer 2D Grafik entsprechend ihrer Daten (Features) zueinander dargestellt. Hierzu werden alle Features eines Datensatzes genommen und auf ein Wertepaar reduziert, die dann als x- und y-Koordinaten verwenden werden können. Eine Linien-Darstellung des trainierten Klassifikations-Modells (oder Decision Boundary) trennt Datenpunkte beider Kategorien voneinander ab. Eine noch nicht zugeordnete neue E-Mail (lila Punkt) kann danach eindeutig durch das fertige Modell als Nicht-Spam identifiziert werden.
Vor- und Nachteile
Supervised Machine Learning hat im Vergleich zu anderen ML-Algorithmen wie z.B. Unsupervised Machine Learning einige Vorteile6,7. Zunächst sind tendenziell weniger Trainingsdaten notwendig, um ein Modell mit guten Ergebnissen zu trainieren. Ein weiterer Vorteil stellt die klare Verknüpfung zwischen den Trainings-Features, deren Ergebnissen und den vordefinierten Klassen dar. Die Ergebnisse der Vorhersagen werden hierdurch nicht nur viel spezifischer, sondern auch einfacher interpretierbar, wie man es bereits im Klassifizierungsbeispiel bei Spam oder Nicht-Spam E-Mails sehen konnte. Jede E-Mail enthält klare Informationen darüber, welche Wörter vorhanden sind und ist eindeutig entweder als Spam oder als Nicht-Spam klassifizierbar. Jedoch ist hierbei die Qualität der benutzten Trainingsdaten entscheidend. Richtig markierte und aussagekräftige Trainingsdaten sorgen meist für eine hohe Genauigkeit der Vorhersagen. Die Notwendigkeit die Trainingsdaten mit Labels zu versehen bzw. sie in eine qualitativ hochwertige Form zu bringen, kann ein durchaus zeitintensiver Prozess sein und damit auch als Nachteil angesehen werden, der höhere Kosten in Personal und Ressourcen erfordert. Deshalb ist es wichtig mit professioneller Data-Science-Beratung zunächst den richtigen Machine Learning Algorithmus für die passende Fragestellung auszuwählen. Dadurch kann bei möglichst niedrigen Kosten der tatsächliche Nutzen maximiert werden.
Fazit
Schlussendlich könnte man die berechtigte Frage stellen, ob sich Investitionen in neue automatisierte Prozesse, die Supervised Machine Learning verwenden, bezahlt machen. Ein kurzes Rechenbeispiel kann durchaus überzeugen: In einer Firma mit 46.000 Mitarbeitern konnte eine manuelle Dateneingabe mit Hilfe von maschinellem Lernen auf ein paar Sekunden verkürzt werden. Nur für die Hälfte der Belegschaft würde eine derartige Zeit Einsparung von 5 Minuten pro Arbeitstag bereits 314 Vollzeitstellen pro Tag entsprechen, die entweder zur Kostenreduktion oder für zusätzliche Mitarbeiter verwendet werden könnten8.
Über den Autor
Dr. Wolfgang Krebs promovierte in Biomedizin, bevor er sich 2017 zu einer Karriere im IT-Sektor als Softwareentwickler entschieden hat, um sich seiner Leidenschaft in Vollzeit zu widmen. Bei der MATHEMA GmbH beschäftigt er sich aktuell nicht nur mit spannenden Aufgaben als Product Owner, Data Scientist und Entwickler, sondern entwickelt sich auch auf dem interessanten Gebiet des Maschinellen Lernens weiter.
Quellenangaben
- Artificial Intelligence vs. Machine Learning vs. Deep Learning: What’s the Difference, Serokell, 10. April 2020. https://medium.com/ai-in-plain-english/artificial-intelligence-vs-machine-learning-vs-deep-learning-whats-the-difference-dccce18efe7f
- Sechs Thesen, wie KI-Prognosen unser Leben verändern werden. Karin Frick, 9. Mai 2019. https://www.gdi.ch/de/publikationen/trend-updates/sechs-thesen-wie-ki-prognosen-unser-leben-veraendern-werden
- Supervised Learning: ein Lehrplan für Maschinen, IONOS, 9. Juni 2020. https://www.ionos.de/digitalguide/online-marketing/suchmaschinenmarketing/was-ist-supervised-learning/
- Kotsiantis, S. (2007). Supervised machine learning: A review of classification techniques. Informatica, 31 , 249–268.
- An In-depth guide to supervised machine learning classification, Badreesh Shetty, Juli 2019. https://builtin.com/data-science/supervised-machine-learning-classification
- Supervised vs Unsupervised Learning: Algorithms and Examples, Silvia Valcheva, Oktober 2019. http://www.intellspot.com/unsupervised-vs-supervised-learning/
- Supervised Learning, datenbanken-verstehen.de, https://www.datenbanken-verstehen.de/lexikon/supervised-learning/
- How machine Learning improves business efficiency – five practical examples, Konrad Budek, 30. August 2018. https://deepsense.ai/machine-learning-business-examples/




