
Owl Racer – Training von KI-Modellen
Owl Racer – Einblicke in das Training von KI-Modellen
Dieser Artikel ist eine Fortsetzung von Owl Racer – Fahrstunden für die KI. Owl Racer ist eine Anwendung, die maschinelles Lernen auf eine spielerische und visuelle Art erfahrbar macht.
Es handelt sich dabei um ein 2D-Rennspiel mit einfacher Steuerung und simplen Metriken für den Fortschritt der einzelnen Fahrzeuge. Über ein grafisches User-Interface (UI) können neue Spiele gestartet oder zu bestehenden Spielen beigetreten werden.
Der Fokus des Projekts liegt vor allem darauf, eine Plattform zu bieten, in der Machine-Learning-Modelle auf Spieldaten trainiert werden, um danach gegen diese als menschlicher Spieler anzutreten, oder alternativ verschiedene Modelle gegeneinander zu testen und zu vergleichen.
Abbildung 1: Mittelschwere Strecke
Aufbau des Projekts
Der Kern des Spiels ist ein Server basierend auf ASP.NET, welcher sämtliche Berechnungen aller wesentlichen Charakteristiken, beispielsweise Positionen und Geschwindigkeiten der Autos, Spielstände und andere Statistiken, übernimmt. Über gRPC können sich verschiedene Clients mit dem Server verbinden, wie zum Beispiel der visuelle Client zur Bereitstellung des UI. Genauere Infos zur Architektur und zu den verwendeten Technologien lassen sich im eingangs erwähnten Artikel finden.
Der Fokus für diesen Artikel liegt auf dem Python-Client, welcher eine Möglichkeit bietet, Maschine-Learning-Algorithmen basierend auf den Spieldaten zu trainieren und auszuführen.
Funktionsweise des Spiels
Im Spiel treten mehrere Autos, jeweils gesteuert durch menschliche Spieler oder durch KI, in einem Rennen aus der Vogelperspektive gegeneinander an. Gesteuert wird dabei mit den Pfeiltasten, um zu beschleunigen, zu bremsen und zu lenken. Ziel ist es, möglichst schnell bestimmte Checkpoints und schließlich auch die Ziellinie zu überqueren. Die Strecke ist dabei durch Gras begrenzt, welches das Auto beim Befahren stark verlangsamt. Aktuell gibt es drei verschiedene Strecken mit unterschiedlichen Schwierigkeitsgraden zur Auswahl:

Abbildung 2: Die verschiedenen Strecken. Nummerierung von links nach rechts: 0, 1, 2
Die Layouts der verschiedenen Strecken in Abbildung 2 sind hauptsächlich dafür gedacht, unterschiedliche Schwierigkeitsgrade für die Machine-Learning-Modelle darzustellen. Während es sich bei Strecke 0 um nicht mehr als einen Kreis handelt, besitzt Strecke 1 sowohl Rechts- als auch Linkskurven. Strecke 2 bietet noch zusätzliche Schwierigkeiten, da sie einerseits schmaler als die anderen beiden Strecken ist und andererseits verschiedene Kurvenformen beinhaltet, welche eine Herausforderung für die Machine-Learning-Algorithmen darstellen.
Die Fortschritte der einzelnen Autos werden über Checkpoints gemessen, deren Vorkommen serverseitig über ein File konfiguriert werden kann. Die Checkpoints sind vor allem von zentraler Bedeutung für das Reinforcement Learning bzw. die Rewardfunktion.

Abbildung 3: Abfrage von Informationen
In Abbildung 3 ist die aktuelle Checkpoint-Konfiguration für Strecke 1 dargestellt. Die Strecke ist dabei in kleine Streifen aufgeteilt, wobei hellere Streifen einem fortgeschritteneren Checkpoint entsprechen. Der Übergang von Weiß zu Schwarz stellt die Ziellinie dar.
Supervised-Modelle
Die Trainingsdaten für die Supervised-Modelle werden durch manuelles Fahren gesammelt. Dabei werden während jeder Zeiteinheit (Tick) die Beobachtungen des Autos (Features) sowie die zugehörige Aktion (Label) aufgezeichnet.
Die wichtigsten Beobachtungen bzw. Features, die für das Training verwendet werden können, sind die Geschwindigkeit des Autos sowie die Distanzen zum Streckenrand, wobei fünf verschiedene Distanzen aufgezeichnet werden, siehe Abbildung 4. Daneben gibt es jedoch auch noch weitere Features, die für das Trainieren verwendet werden können beispielsweise wird überprüft, ob das Auto in die richtige Richtung fährt oder sich gerade im Gras, also außerhalb der Strecke, befindet.

Abbildung 4: Messung der Distanzen zum Streckenrand.
Die möglichen Aktionen bzw. Labels für das Training ergeben sich aus den Steuerungsmöglichkeiten, die dem Fahrzeug zur Verfügung stehen, siehe Tabelle 1.
|
Label |
Zugehörige Aktion |
|
0 |
Keine Aktion, Idle |
|
1 |
Beschleunigen |
|
2 |
Bremsen |
|
3 |
Beschleunigen und nach links lenken |
|
4 |
Beschleunigen und nach rechts lenken |
|
5 |
Nach links lenken |
|
6 |
Nach rechts lenken |
Tabelle 1: Aktionen und zugehörige Labels.
Werden zum Beispiel die Distanzen zum Streckenrand und die Geschwindigkeit des Autos als Features fürs Training verwendet, sehen die generierten Trainingsdaten folgendermaßen aus (Abbildung 5):

Abbildung 5:Beispiel für Trainingsdaten
Beim Training eines Supervised-Modells werden die Modellparameter so optimiert, dass sie aus gegebenen Features die richtige Aktion vorhersagen. Hier ist jedoch Vorsicht geboten: Die korrekte Zuordnung der Labels ergibt sich daraus, wie beim Generieren der Trainingsdaten gefahren wurde. Das trainierte Modell wird also den Fahrstil der Person nachahmen, welche die Daten aufgezeichnet hat. Daraus ergeben sich weitere Schwierigkeiten, auf die wir im Folgenden eingehen.
Wenn Distanzen und Geschwindigkeit als Features aufgenommen werden, kann ohne zusätzliche Informationen nicht unterschieden werden, ob ein Auto in die richtige Richtung fährt. Nimmt man nun allerdings die Fahrtrichtung als Feature mit auf, dann gibt es zwei Szenarios: Entweder beim Generieren der Trainingsdaten wird ausschließlich in die richtige Richtung gefahren, dann hat das neue Feature keinen Nutzen fürs Training.
Alternativ kann man versuchen, beim Aufzeichnen der Daten gelegentlich absichtlich in die falsche Richtung zu fahren, in der Hoffnung, dass infolgedessen dem Modell gezeigt wird, wie man richtig umkehrt. In der Praxis führt dies jedoch dazu, dass das Modell dann auch manchmal absichtlich in die falsche Richtung fährt. Analog verhält es sich mit dem Fahren ins Gras. Ohne weitere Veränderungen kann das Modell nicht wissen, was zu tun ist, wenn ins Gras gefahren wird. Fährt man aber nun beim Generieren der Trainingsdaten absichtlich ins Gras, dann wird dieses unerwünschte Verhalten vom resultierenden Modell ebenfalls nachgeahmt.
Die große Abhängigkeit vom Fahrstil des trainierten Modells beim Sammeln der Trainingsdaten macht es schwierig, die Performance verschiedener Modelle objektiv zu vergleichen. Zudem kann das Modell auch niemals besser fahren als man selbst. Unter diesen beiden Gesichtspunkte wäre es von Vorteil, über optimale Trainingsdaten zu verfügen, was uns zum Bereich des Reinforcement Learning bringt.
Reinforcement Learning
Reinforcement Learning unterscheidet sich vom Supervised Learning darin, dass hier keine optimale Strategie vorab vorgegeben bzw. bekannt ist. Stattdessen lernt der Agent (das Auto) durch direkte Interaktion mit der Umgebung (dem Server). Der Agent befindet sich in einem bestimmten Zustand (State) und führt eine Aktion (Action) aus. Daraufhin erhält er von der Umgebung eine Rückmeldung über seinen neuen Zustand und den Belohnungswert (Reward) für seine Aktion.
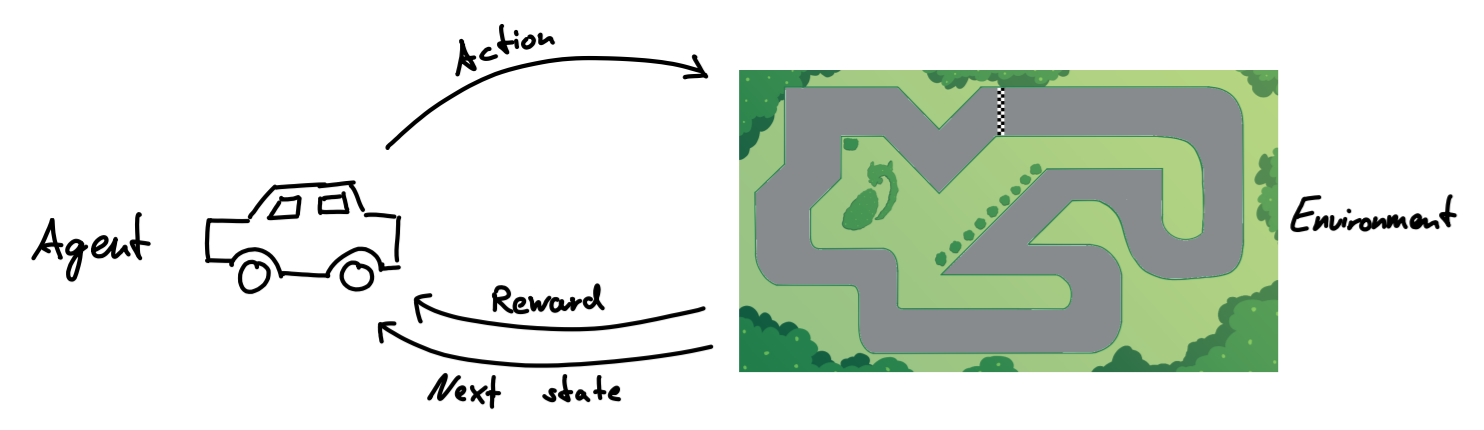
Abbildung 6: Prinzip von Reinforcement Learning.
So könnte beispielsweise das Überfahren von Checkpoints positiv und das Verlassen der Strecke negativ belohnt werden. Das Ziel ist es, durch die erlernten Erfahrungen eine optimale Strategie zu entwickeln. Ein Vorteil davon ist, dass das resultierende Modell potenziell besser fahren kann als ein Mensch, oder in komplizierteren Szenarios auch Strategien herausfinden kann, die für einen Menschen nicht direkt ersichtlich sind.
Aktuell ist ein simpler Q-Learning-Algorithmus für das Reinforcement Learning implementiert. Dieser approximiert eine sogenannte Q-Funktion, die jedem (State, Action)-Paar einen Wert zuordnet, welcher dem erwarteten Reward für eine bestimmte Aktion in einem bestimmten Zustand entspricht. Unter der Annahme einer optimalen Q-Funktion wird dann zu einem gegebenen Zustand die Aktion mit dem höchsten Q-Wert gewählt.
Die Werte der Q-Funktion werden durch Training nach und nach angepasst: Zunächst werden alle Werte zufällig initialisiert. Mit jeder neuen Erfahrung werden die Werte aktualisiert, um besser vorherzusagen, welche Aktion langfristig den höchsten Reward bringt.
Dabei spielen die beiden Hyperparameter Lernrate (α) und Discount-Faktor (γ) eine zentrale Rolle:
- Die Lernrate bestimmt, wie stark neue Erkenntnisse in die Q-Funktion eingehen.
- Der Discount-Faktor legt fest, wie wichtig zukünftige Rewards im Vergleich zu sofortigen Rewards sind.
Zu Beginn wählt das Auto hauptsächlich zufällige Aktionen. Mit zunehmendem Training werden jedoch bevorzugt die Aktionen ausgewählt, die den höchsten Q-Wert besitzen.
Ein weiterer wichtiger Parameter ist die Explorationsrate (ε), die festlegt, mit welcher Wahrscheinlichkeit das Modell trotzdem eine zufällige Aktion wählt. Diese Exploration ist entscheidend, um neue, potenziell bessere Strategien zu entdecken.
Herausforderungen und Feinabstimmungen beim Reinforcement Learning
Diskretisierung der Eingabefeatures:
Ein zentraler Punkt im Reinforcement Learning ist, dass alle möglichen (State, Action) -Kombinationen ausreichend häufig evaluiert werden. Da die Eingabefeatures (wie Geschwindigkeit oder Abstand zur Streckenbegrenzung) annähernd kontinuierliche Werte annehmen, könnte dies jedoch zu einer sehr großen Anzahl von Zuständen führen. Um dieses Problem zu umgehen, werden die Eingaben in sogenannte Buckets aufgeteilt, also Wertebereiche, welche die Features in diskrete Eingaben umwandeln. Hierbei sind sowohl Anzahl und Größe der Buckets entscheidende Kenngrößen für den Erfolg des Trainings.
Gestaltung der Rewardfunktion:
Die Rewardfunktion ist das einzige Feedback, welches der Agent für seine Aktionen erhält, und spielt daher mitunter die wichtigste Rolle im Training. Aktuell sind die folgenden Rewards implementiert:
Ereignis
1 Überfahren eines Checkpoints
2 Crash ins Gras
3 Fahren in die falsche Richtung
4 Anderes Verhalten
Reward
10x n Punkte pro Checkpoint, wobei n mit dem Streckenfortschritt ansteigt
-500 Punkte
-5 Punkte pro Zeiteinheit
-1 Punkt pro Zeiteinheit
Tabelle 2: Zusammensetzung der Rewardfunktion.
Da das Überfahren der Checkpoints die einzige Möglichkeit für positiven Reward ist, richtet der Agent im Idealfall seine Strategie darauf aus, Checkpoints effizient zu erreichen. Die Gewichtung mit führt dazu, dass spätere Checkpoints mehr belohnt werden. Des Weiteren soll über Punkt 4 sichergestellt werden, dass der Agent nicht einfach an einer Stelle stehen bleibt oder allzu vorsichtig fährt, sondern sich sozusagen etwas „beeilt“.
Variable Hyperparameter:
Wie bereits erwähnt, beeinflussen drei Hyperparameter das Training entscheidend: Discount-Faktor (γ), Lernrate (α) und Explorationsrate (ε). Die Werte der Lern- und Explorationsrate werden im Verlauf des Trainings angepasst, um das Verhalten des Agenten in neuen Situationen zu optimieren.
Das Ziel ist, dass der Agent neue Strategien schneller lernt und seine Entscheidungen sorgfältiger erkundet. Momentan startet ein neuer Durchlauf (Run), sobald das Auto crasht oder einen bestimmten Negativscore erreicht. Dabei fährt es immer wieder durch die gleichen Streckenabschnitte, bevor neue erreicht werden. Um zu verhindern, dass die Anfangsabschnitte übermäßig das Lernen beeinflussen, erhöhen sich die Lern- und Explorationsrate, je näher das Auto dem größten bisher erreichten Checkpoint kommt.
(Miss-)Erfolge beim Reinforcement Learning
Das Training des Modells im Reinforcement Learning bietet viele Stellschrauben: Angefangen bei den Hyperparametern über den Score bis hin zur Diskretisierung der Features – jede Veränderung kann das Verhalten des Modells maßgeblich beeinflussen. Da jedoch die Wechselwirkungen zwischen den einzelnen Parametern komplex sind, ist es oft schwer abzuschätzen, wie sich Anpassungen konkret auf die Leistung des Modells auswirken werden. So kann eine kleine Anpassung der Lernrate oder eine feinere Einteilung der Diskretisierungs-Buckets unerwartete und sogar gegenläufige Ergebnisse auf verschiedenen Strecken liefern.
Das hat Einfluss auf die Trainingsperformance bei den verschiedenen Strecken. Auf Strecke 0, welche eine breite Fahrbahn und weite Kurven aufweist, zeigt das Modell auch mit sehr grober Diskretisierung in der Regel gute Fahrleistungen. Ähnlich verhält es sich bei Strecke 1, die einen mittleren Schwierigkeitsgrad darstellt, aber ebenfalls gut mit den bisherigen Trainingskonfigurationen gemeistert wird. Interessant ist, dass ein Modell, welches auf Strecke 0 trainiert wurde, relativ gut auf Strecke 1 fahren kann und teilweise auch die einfacheren Abschnitte von Strecke 2 bewältigt. Dies zeigt, dass durchaus auf ähnliche Strecken generalisiert werden kann.
Problematisch wird es jedoch bei Strecke 2. Diese enthält schmale Fahrspuren und enge Kurven mit teils unüblichen, spitzen Formen. Hier treten Herausforderungen wie das wiederholte Verlassen der Fahrbahn oder ein ständiges Anpassen der Aktionen auf, um auf der schmalen Strecke die Balance zwischen Geschwindigkeit und Kontrolle zu finden. Um diese spezifischen Probleme zu adressieren, könnten speziellere Anpassungen erforderlich sein, wie etwa eine angepasste Rewardfunktion, die negative Belohnungen für das Verlassen der Strecke besonders stark gewichtet, oder eine zusätzliche Diskretisierung, die feinere Zustandsübergänge ermöglicht.
Kompatibilität und Ausführung der verschiedenen Modelle
Um alle verschiedenen Modelle mit demselben Skript auszuführen und die Kompatibilität mit anderen Clients zu gewährleisten, werden die trainierten Modelle im ONNX-Format gespeichert. Das Skript kommuniziert mit dem Server über ein Interface basierend auf gymnasium und durchläuft eine Endlosschleife, in der die Beobachtungen des Autos verarbeitet und als Eingabe an das Modell weitergegeben werden. Das Modell gibt für jede mögliche Aktion eine Wahrscheinlichkeit oder einen Score zurück. Basierend darauf wird die beste Aktion oder eine zufällige Aktion entsprechend der Verteilung ausgewählt und an den Server übermittelt.
Für die aktuelle Implementierung des Q-Learning-Algorithmus wird die Q-Funktion über einen Umweg als lineares torch-Modell realisiert, sodass die Ergebnisse in das ONNX-Format überführt werden können.
Wie oben beschrieben, ist das Ergebnis des Q-Learnings eine Qualitätsfunktion, die (State, Action) -Paare bewertet und den erwarteten Reward für jede Kombination liefert. Diese Funktion kann auch als sogenannte Lookup-Tabelle interpretiert werden, indem die möglichen Zustände als Zeilenindizes und die möglichen Aktionen als Spaltenindizes aufgefasst werden. Mit dieser Struktur lassen sich die Trainingsergebnisse beispielsweise als .csv-Datei speichern und für das Ausführen des Modells nutzen.
Um die Q-Learning-Ergebnisse als ONNX-Modell verfügbar zu machen, lässt sich die Lookup-Tabelle zunächst als Torch-Modell darstellen und dann mithilfe einer eingebauten torch-Funktion in das ONNX-Format konvertieren. Hierbei kann man die Lookup-Tabelle als eine -Matrix interpretieren, wobei die Anzahl aller Zustände und die Anzahl der möglichen Aktionen ist. Die Umsetzung in torch erfolgt also einfach als Linear-Layer ohne Bias, dessen Gewichtsmatrix die Werte der Lookup-Tabelle enthält.
Um den Aktionsscore für eine gegebene Beobachtung zu berechnen, wird die Beobachtung zunächst in den entsprechenden Zustand umgewandelt und dann als Vektor kodiert, wobei der Vektor die Länge hat und nur an Position eine 1 enthält. Durch das Anwenden des linearen Layers auf diesen Vektor erhält man die -te Zeile der Lookup-Tabelle, die den Score jeder möglichen Aktion für den Zustand darstellt.
Aktueller Stand und Ausblick auf die Zukunft
Aktuell ermöglicht das Owl Racer Projekt nicht nur das Training und die Auswertung von Algorithmen innerhalb des Spiels, sondern schafft auch eine Plattform für zukünftige Modell- und Architekturverbesserungen. Obwohl es Probleme bei der schwierigen Strecke gibt, zeigt der Q-Learning-Algorithmus gute Ergebnisse auf einfachen und mittelschweren Strecken und bietet eine solide Grundlage für das Verständnis und die Weiterentwicklung des Reinforcement Learning.
Ein potenzieller nächster Schritt wäre, diese Ergebnisse zur Erzeugung von „perfekten“ Trainingsdaten zu nutzen, anhand derer das Verhalten der unterschiedlichen Supervised-Modelle verglichen werden kann.
Zur Verbesserung des Reinforcement Learning könnte ein Algorithmus für Deep Q-Learning (DQL) implementiert werden. DQL nutzt neuronale Netzwerke, um komplexere Zusammenhänge in Zustands- und Aktionsräumen zu lernen und ermöglicht es dem Modell, aus einem weitaus höheren Spektrum an Eingaben zu lernen, ohne dabei auf eine intensive Diskretisierung angewiesen zu sein. Mit DQL könnten die KI-Agenten zukünftig auch anspruchsvollere Strecken meistern. Durch die größere Flexibilität der neuronalen Netze wären die Agenten zudem robuster gegenüber neuen, nicht bekannten Streckenlayouts.
Ein weiterer Ausblick ist die Implementierung zufälliger Startpositionen, um die Generalisierungsfähigkeit der Modelle zu verbessern. Momentan beeinflusst die starre Struktur des Trainingsdurchlaufs, in dem immer wieder die gleichen Streckenabschnitte befahren werden, das Verhalten der Agenten. Durch zufällige Startpositionen könnte der Trainingsprozess diversifiziert und die Abhängigkeit von spezifischen Streckenmerkmalen reduziert werden. Dazu müsste jedoch die Rewardfunktion weiterentwickelt werden, damit das Modell nicht nur auf bestimmte Checkpoints, sondern auf den gesamten Streckenverlauf optimal reagiert.
Diese Perspektiven bieten interessante Möglichkeiten für die Weiterentwicklung des Projekts als Experimentierumgebung für KI-gestütztes Fahren.
Persönliche Erfahrungen mit dem Projekt
Da es sich um ein bereits bestehendes Projekt handelte, das hauptsächlich in Bezug auf die Machine Learning-Skripte auf einen neuen Stand gebracht und erweitert werden sollte, hat sich das Verständnis der verschiedenen Projektkomponenten und deren Funktionalität als erste größere Hürde dargestellt. Vor allem die Kommunikation zwischen dem Server und dem Python-Client anzupassen und zu überprüfen war für mich eine neue Herausforderung.
Das Owl Racer Projekt hat sich jedoch schnell als ideale Plattform erwiesen, um erste praktische Erfahrungen im Training von KI-Modellen zu sammeln. Ohne Vorkenntnisse im Bereich Machine Learning bin ich früh auf einige Schwierigkeiten gestoßen, doch gerade diese Hindernisse haben mir wertvolle Einblicke und zahlreiche neue Erfahrungen beschert.
Zum ersten Mal habe ich mich intensiv mit verschiedenen Modelltypen, Algorithmen und dem Ansatz des Reinforcement Learning auseinandergesetzt. Themen wie das richtige Abstimmen von Hyperparametern, die richtige Art des Preprocessings und die sinnvolle Auswahl von Features und Aktionen waren essenziell für die Leistungsfähigkeit der Modelle. Dieser Teil des Projekts hat mir geholfen, ein fundiertes Verständnis für die grundlegenden Prinzipien des maschinellen Lernens zu entwickeln.
Im Verlauf des Projekts habe ich zudem Einblicke in viele relevante Data-Science-Tools und -Packages bekommen. Der Umgang mit Libraries wie pandas, scikit-learn, PyTorch, ONNX und MLflow war neu für mich und die Arbeit am Owl Racer hat mir geholfen, Routine in der praktischen Anwendung dieser Werkzeuge zu entwickeln.
Die Implementierung des Reinforcement Learnings hat sich als besonders spannend erwiesen. Ursprünglich als Hilfsmittel zur Generierung von Trainingsdaten gedacht, hat es sich rasch zu einem zentralen Element entwickelt, das Geduld und viel Experimentierfreude erfordert hat. Das kontinuierliche visuelle Feedback während des Trainings, zusätzlich zu den abstrakten Metriken, hat den Lernprozess jedoch sehr motivierend und interessant gestaltet.
Rückblickend hat das Projekt nicht nur mein Verständnis für KI-Modelle und die Arbeit an größeren Programmierprojekten erweitert, sondern auch mein Interesse an den theoretischen Aspekten des Machine Learnings geweckt. Die praktischen Einblicke haben meine Motivation bestärkt, mich in meinem Studium und meiner weiteren Laufbahn intensiver mit den zugrunde liegenden mathematischen Prinzipien auseinanderzusetzen.
Während meiner Recherchen bin ich außerdem auf interessante Artikel und Literatur gestoßen, die Verbindungen zwischen Machine Learning und anderen mathematischen Disziplinen wie der Kategorientheorie oder der algebraischen Topologie aufzeigen. Diese teils unerwarteten Überschneidungen eröffnen neue Perspektiven und könnten einen spannenden Ansatz für künftige Projekte bieten.
Abschließend möchte ich mich noch bei Anna Holzmann, Fabian Witt und Diego Correa für die äußerst angenehme Zusammenarbeit und intensive Unterstützung während meiner Arbeit an dem Projekt bedanken.
Sandro Erras studiert derzeit Mathematik im Master an der TU Berlin und war bei der MATHEMA GmbH als Werkstudent im Bereich Data & AI für das Update und die Erweiterung des Owl Racer Projekts zuständig.





